There is a ton of information these days on every single phase involved in building AI algorithms, and this is great!
This covers loading/preparing data, feature engineering, training, testing, hyper-parameterization, validation, explainability, MLOps, and deployment.
Overlooking End-Users in AI Applications
At the same time, I am puzzled to see how little is mentioned about the “end-user”: the end-user being a business person with no AI background interacting with the software.
Even if AI has led to many “automated” AI applications (for instance, autonomous vehicles, trading bots, etc), most companies need end-users to “collaborate”/interact with an AI engine.
Vincent Gosselin
Let’s take two examples:
- QSR Store Sales Forecast
- A two-month Cash Flow Prediction for a large Franchised brand.
In Example 1, a QSR store manager connects to the new forecasting software. Through an ergonomic GUI, she/he can generate next week’s sales forecast (created by the AI engine). Then, she/he just discovered 5 minutes ago that a competitor across the road is running a new promotion today. She/He may then opt to lower the generated forecast by 10% during peak hours. Here, the end-user needs to modify the output of the forecast engine.
In Example 2, the company treasurer wants to run the Cash Flow Prediction for the next two months. However, he wants to play with different inflation values and evaluate the impact on the forecast. Here, the end-user wants to control an input parameter (the inflation rate) to the AI Engine.
There are countless other examples where end-users need to modify an AI engine's input or output. This is an integral part of the Decision Process.
Taipy's Capabilities to enhance end-user interaction with AI
To address these situations, we defined (as part of the Taipy open source team) the concept of “scenario” and “data nodes”. A scenario is nothing more than the execution of your algorithm (pipeline) given a set of input information (input data nodes).
We have also implemented three essential capabilities:
1. Data Nodes
Ability to model pipelines as a sequence of Python tasks as well as Data Nodes (anything that can be an input or an output of a Python task). A data node can connect to any data format (SQL, NoSQL, CSV, JSON, etc) or a parameter (a Python object, i.e., A date entered by the end-user through the graphical interface).
2. Scenarios
Ability to record each pipeline execution (inside a registry). We call such execution a ‘scenario’.
3. Scenario comparison
Ability to retrieve past/registered scenarios, compare them, track them, etc.
We decided to provide two options for defining your pipeline in Taipy: Programmatically or using a Visual Code Graph Editor.
Let's take an example
1. Create a pipeline
Let’s take a straightforward pipeline case with:
- A single task: “predict”, calling the inference of an AI engine
- 2 input Data Nodes: ‘historical_temperature” and “date_to_forecast”.
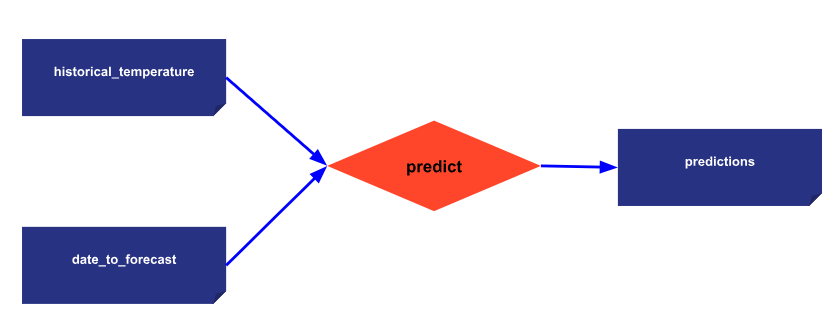
To create this pipeline, with Taipy, we have two options:
Option 1: Programmatical Configuration
We can dive into Python code. This script creates a scenario_cfg object:
from taipy import Config
# Configuration of Data Nodes
historical_temperature_cfg = Config.configure_data_node("historical_temperature")
date_to_forecast_cfg = Config.configure_data_node("date_to_forecast")
predictions_cfg = Config.configure_data_node("predictions")
# Configuration of tasks
predict_cfg = Config.configure_task(id="predict",
function=predict,
input=[historical_temperature_cfg, date_to_forecast_cfg],
output=predictions_cfg)
# Configuration of a scenario configuration
scenario_cfg = Config.configure_scenario(id="my_scenario", task_configs=[predict_cfg])
Option 2: Graphical Editor Configuration
Or, we can use Taipy Studio, the Pipeline/DAG Graphical Editor that enhances pipelines creation. (It's a VS Code extension)
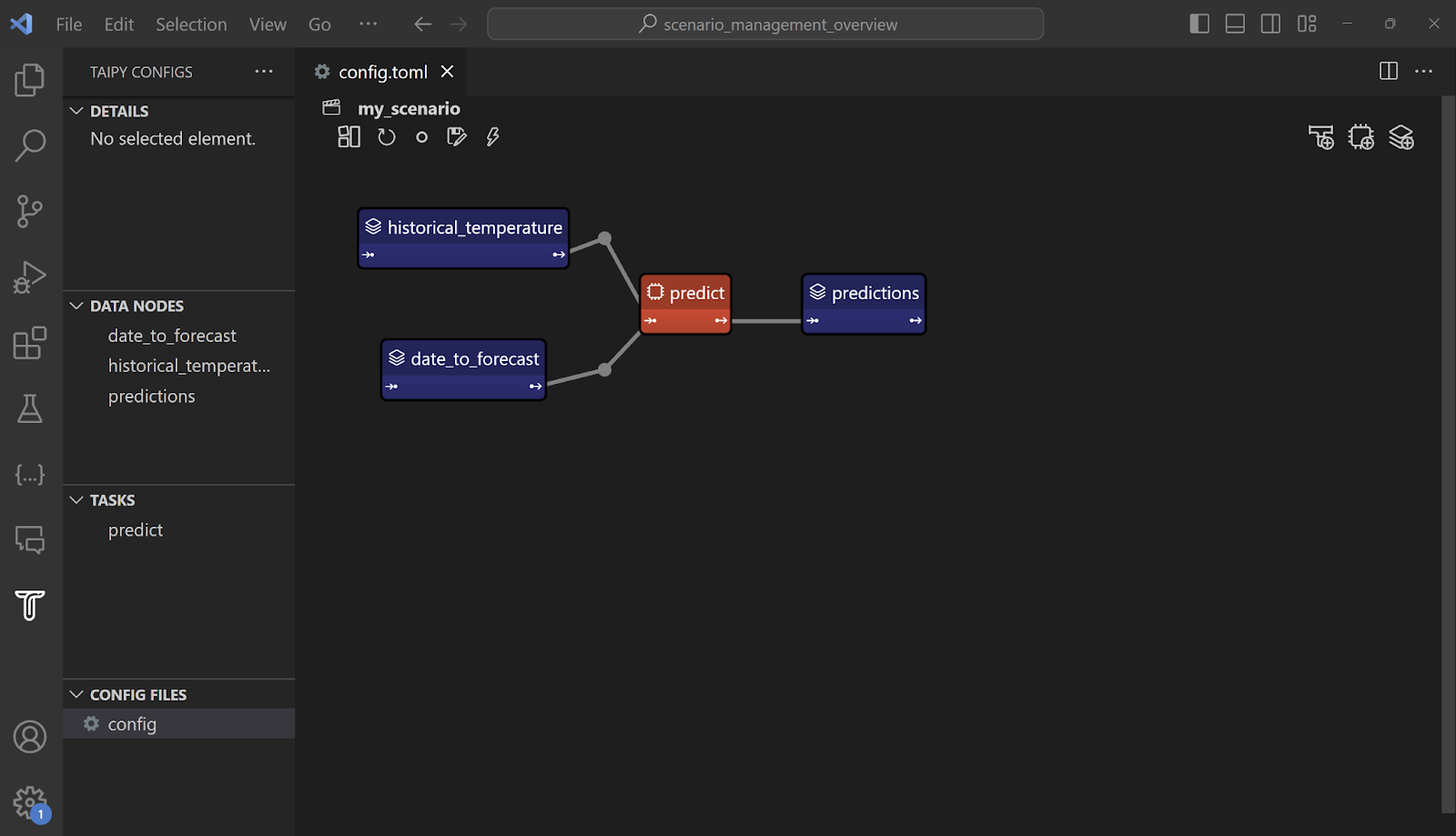
The scenario_cfg object is then created by loading the previous diagram and saved as a TOML file.
Config.load('config.toml')
# my_scenario is the id of the scenario configured
scenario_cfg = Config.scenarios['my_scenario']
2. Execute different scenarios
Scenarios are just instances of the previous pipeline configuration.
Here:
1. We create a scenario (an instance of the pipeline configuration above)
2. We initialize its input data nodes
3. We execute it (tp.submit())
import taipy as tp
# Run of the Taipy Core service
tp.Core().run()
# Creation of the scenario
scenario = tp.create_scenario(scenario_cfg)
# Initialize the 2 input data nodes
scenario.historical_temperature.write(data)
scenario.date_to_forecast.write(dt.datetime.now())
# execution of the scenario
tp.submit(scenario)
print("Publish the predictions", scenario.predictions.read())Note that behind the screen, the execution of a given scenario is registered, i.e., an automatic storage of information related to each data node used at the time of execution.
Benefits
This relatively “simple” scenario management process defined in this article allows for:
1. A rich set of user functionalities such as:
- Easy Retrieval of all scenarios over a given period and their associated input/output data nodes allows easy data lineage.
- Comparing two or more scenarios based on some KPIs: the value of a given data node.
- Tracking over time a given KPI
- Re-executing a past scenario with new values (can change the value of a given data node)
2. Full pipeline Versioning: Essential for quality Project management
Overall pipeline versioning is badly needed when new data nodes/sources are introduced or a new version of a given Python code (avoiding incompatibilities with previously run scenarios).
3. Narrowing the gap between Data Scientists/Developers & End-users
By providing access to the entire repository of end-user scenarios, data scientists and Python devs can better understand how end-users use the software.
And to go further
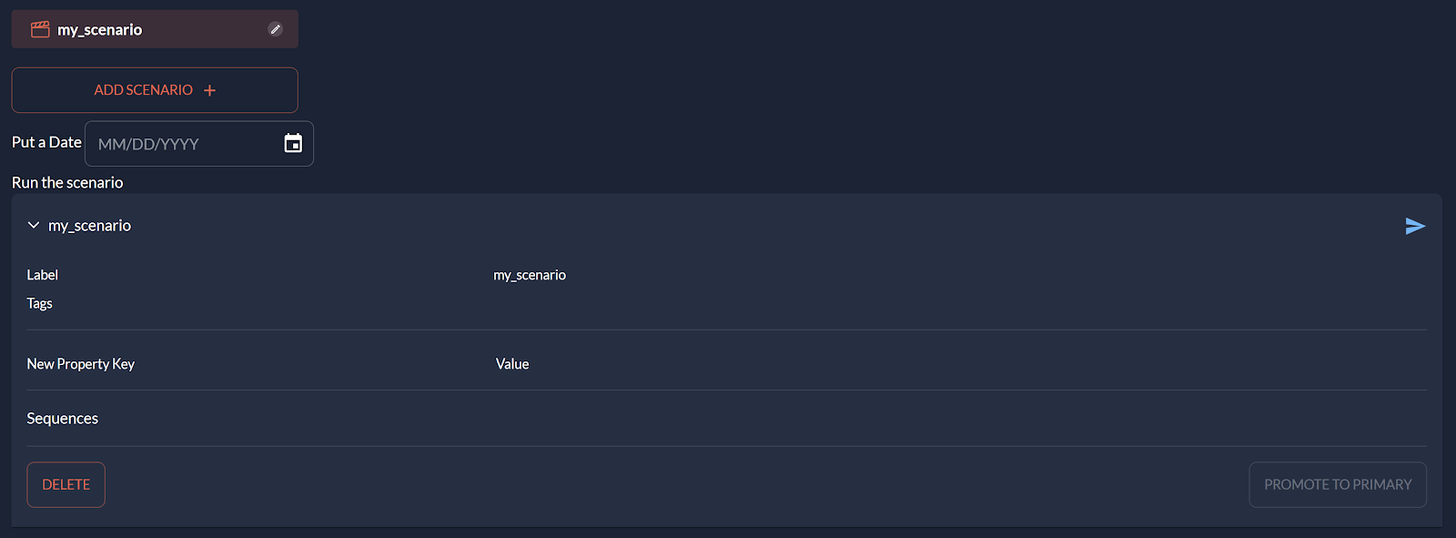
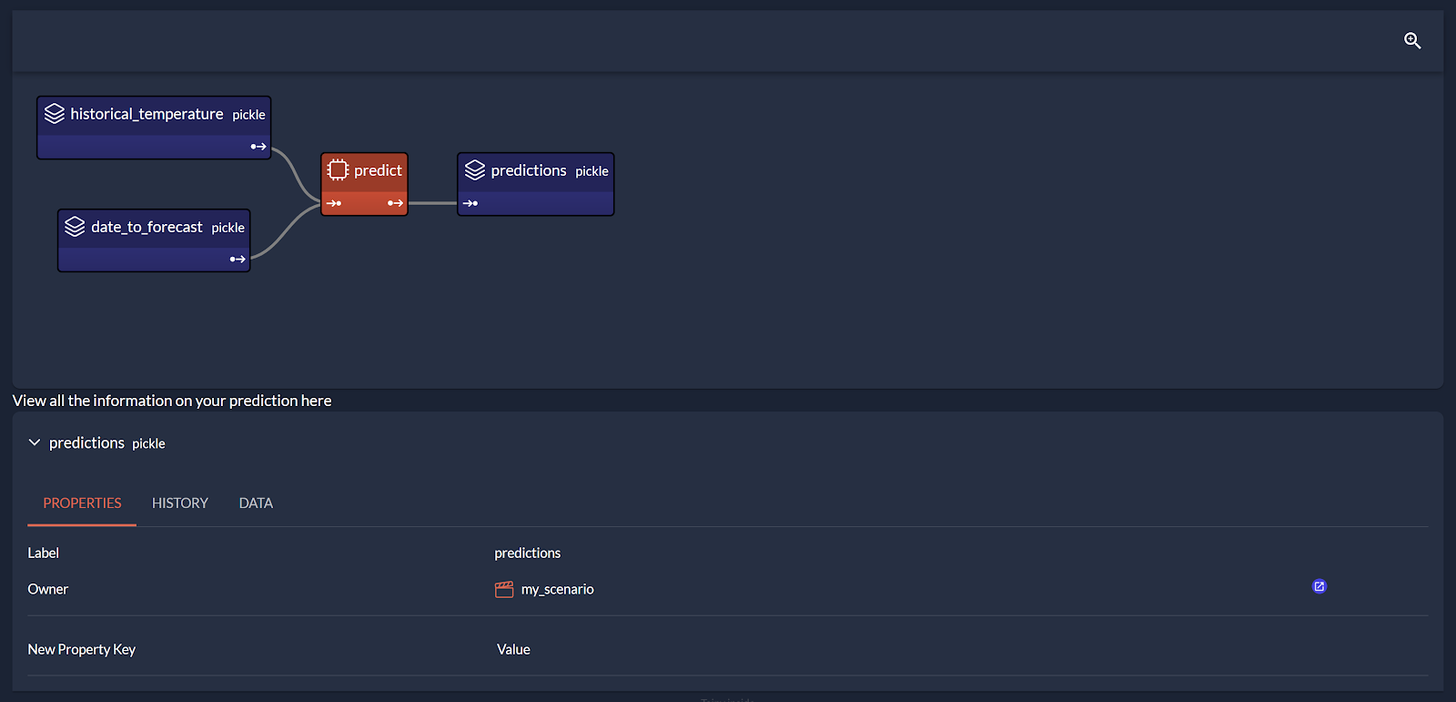
To help this process, we found it helpful to provide specific graphical objects to explore past scenarios visually, display their input and output data nodes, modify them, re-execute scenarios, etc.
For this purpose, we extended Taipy’s graphical library to provide a new set of graphical components for Scenario visualization.
Here’s an example of such a scenario ‘navigator’.
Conclusion
This is our interpretation of scenario management. We hope such an article will trigger more interest and discussion on this crucial topic and lead to better AI software and, ultimately, better decisions.
- Copied!